





需求分析
- AI独立作为独立外部系统,非侵入业务系统
- AI能力可横向纵向扩展,可支持多个供应商能力及每个供应商多种类能力
- AI可独立配置,配置持久化数据库,当请求到达AI模块时,动态添加配置后再最终调用能力
- Manager权限模块支持Auth2.0的授权码授权模式和账号密码授权模式
- Manager模块支持多种负载策略
- 配置页面前后端分离,支持多数据源
- AI模块有限流熔断能力
- 支持集群部署,集群高可用
1). 应参照六边形架构设计。
2). 使用工厂模式,策略模式和模板模式保证能力的横向和纵向扩展。
3). 使用代理模式可以方便的实现此需求,可配置项可以配置几个层级。
4). Spring-auth-server可以支持此功能,支持配置clientId。
5). 使用负载均衡器实现,Ribbon为常见策略,安全考虑可使用loadbalance定制。
6). 前后端分离,配置多数据源插件。
7). 使用谷歌Guava搭配Redis可实现,或者使用Reddisson RRLimite。
8). 使用Raft协议+RPC实现(目前蚂蚁金融有开源项目JRaft,也可自己实现)。
设计概述
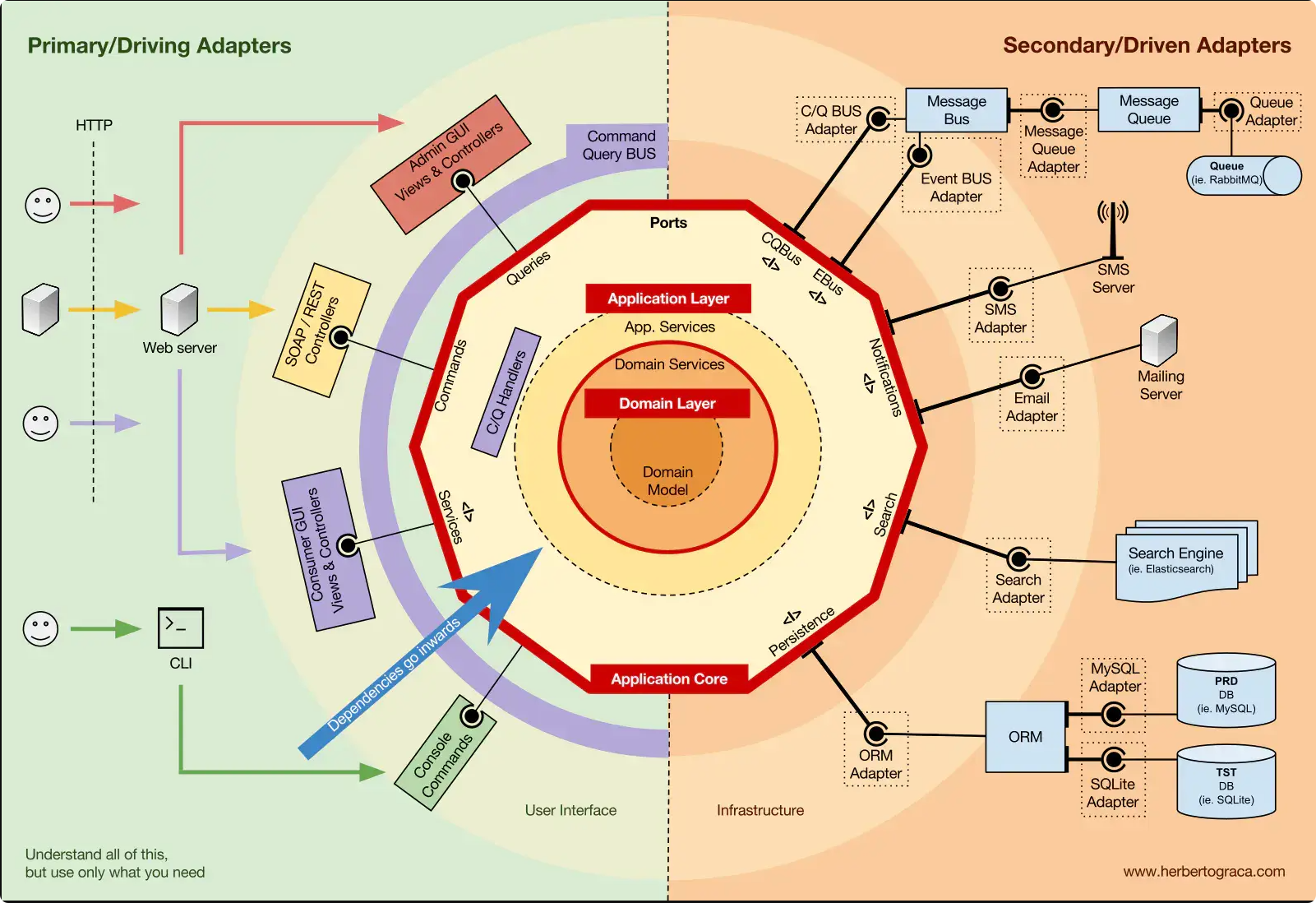
六边形架构
Hexagonal Architecture
2005年Alistair Cockburn提出的Hexagonal Architecture(六边形架构又称端口适配器模式),它把软件系统看做一个六边形,其中有三组组件构成:核心业务逻辑(Domain),输入和输出端口(Ports)以及适配器(Adapters)。这些组件通过一系列接口进行交互,实现内部的业务逻辑,并通过端口和适配器与外部系统进行交互。
六边形架构基于三个原则和技术:
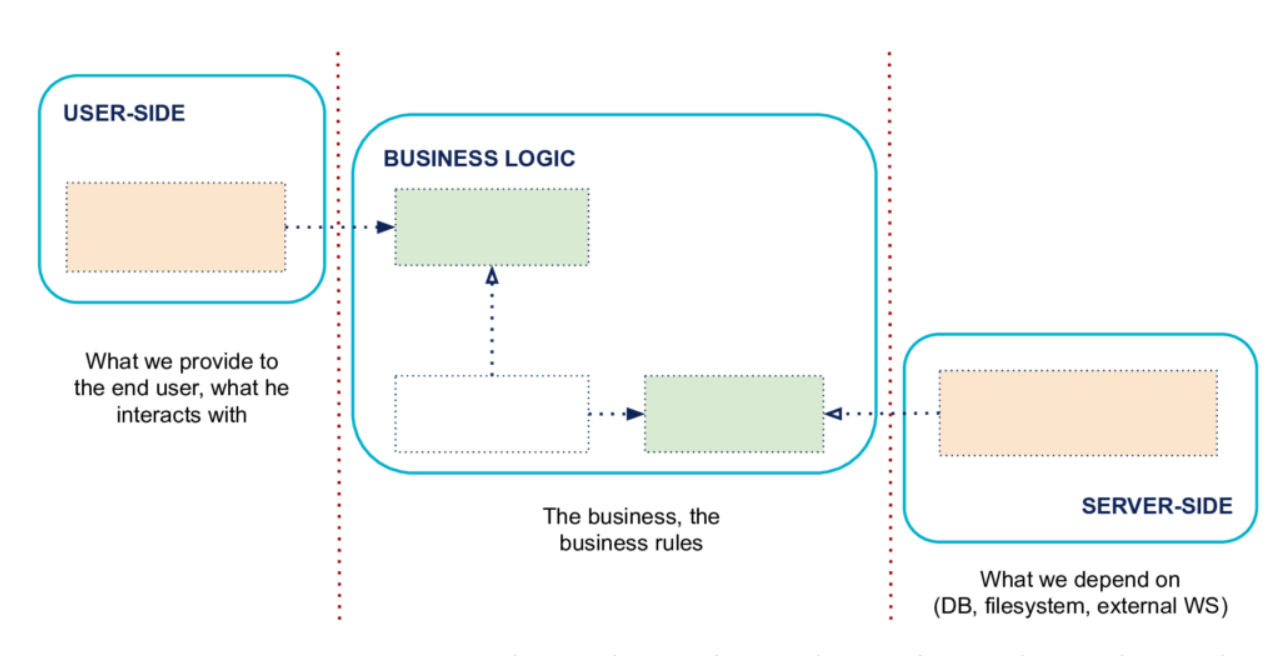
- 明确地分离用户端、业务逻辑和服务器端
- 依赖关系从用户端和服务器端转移到业务逻辑
- 通过使用端口和适配器隔离边界
同时作者给出了代码示例
class Program
{
static void Main(string[] args)
{
// 1. Instantiate right-side adapter ("go outside the hexagon")
IObtainPoems fileAdapter = new PoetryLibraryFileAdapter(@".\Peoms.txt");
// 2. Instantiate the hexagon
IRequestVerses poetryReader = new PoetryReader(fileAdapter);
// 3. Instantiate the left-side adapter ("I want ask/to go inside")
var consoleAdapter = new ConsoleAdapter(poetryReader);
System.Console.WriteLine("Here is some...");
consoleAdapter.Ask();
System.Console.WriteLine("Type enter to exit...");
System.Console.ReadLine();
}
}
public PoetryReader(IObtainPoems poetryLibrary)
{
this.poetryLibrary = poetryLibrary;
}
从示例可以看出,首先是实例化一个fileAdapter,然后实例化业务类poetryReader,将fileAdapter注入到poetryReader,最后将poetryReader注入到客户端consoleAdapter。这里的PoetryReader不依赖于PoetryLibraryFileAdapter,而是依赖于IObtainPoems,PoetryLibraryFileAdapter和PoetryReader是松耦合的。
fileAdapter的定义依赖于业务(此处为继承依赖关系),但在运行时poetryReader可以在实践中控制fileAdapter的实例,这又是依赖关系反转的典型(SOLID的D),如果没有IObtainPoems接口,业务代码的定义将依赖于服务器端代码。
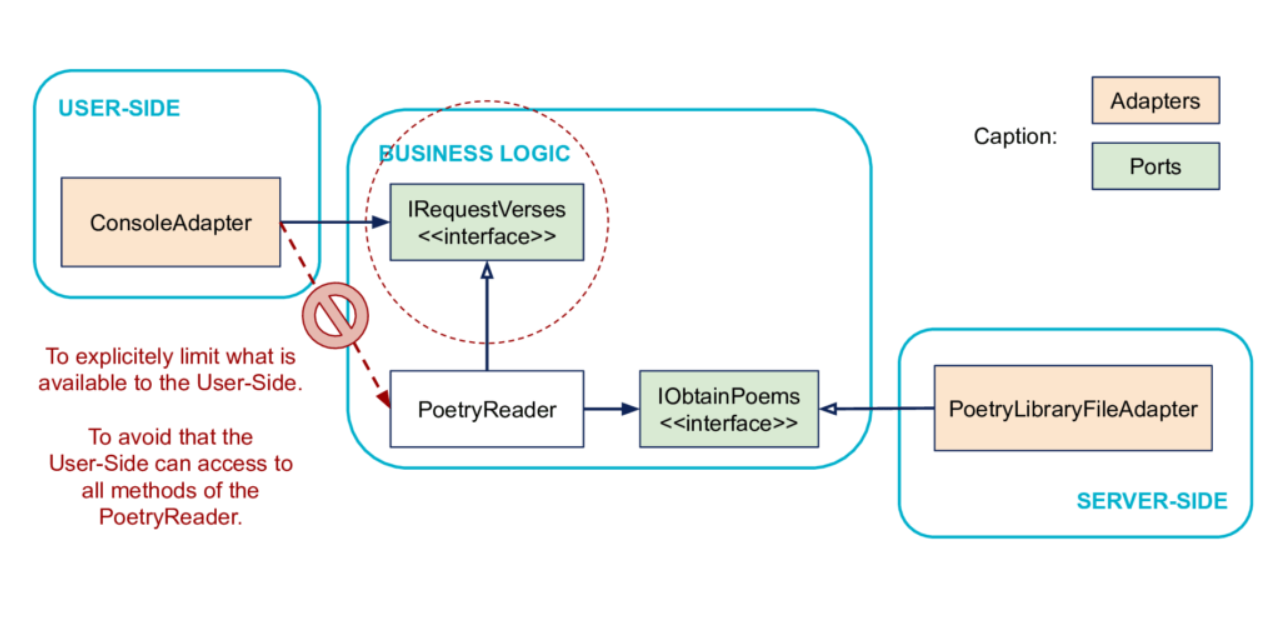
如上图表示,客户端要明确需要的服务并且避免直接依赖服务端具体实现。
2008年Jeffrey Palermo提出了Onion Architecture(洋葱架构),每个层/圈封装或隐藏内部的实现细节,并向外层公开接口。所有的层也需要提供便于内层消费的信息。其目的是最小化层与层之间的耦合,最大化跨层垂直切面内的耦合。我们在较深的层定义抽象接口,并在最外层提供其具体实现。洋葱架构理论更细化指导了分层架构的设计实现,这里不再深入洋葱架构,洋葱架构重心在核心业务侧不在边界侧。
无论是六边形还是洋葱架构,都明确指明了外部系统应该使用端口适配器来实现。
这里我们不需要考虑领域业务实现所以我们的重心不在洋葱架构,AI在六边形架构的位置关系如图。
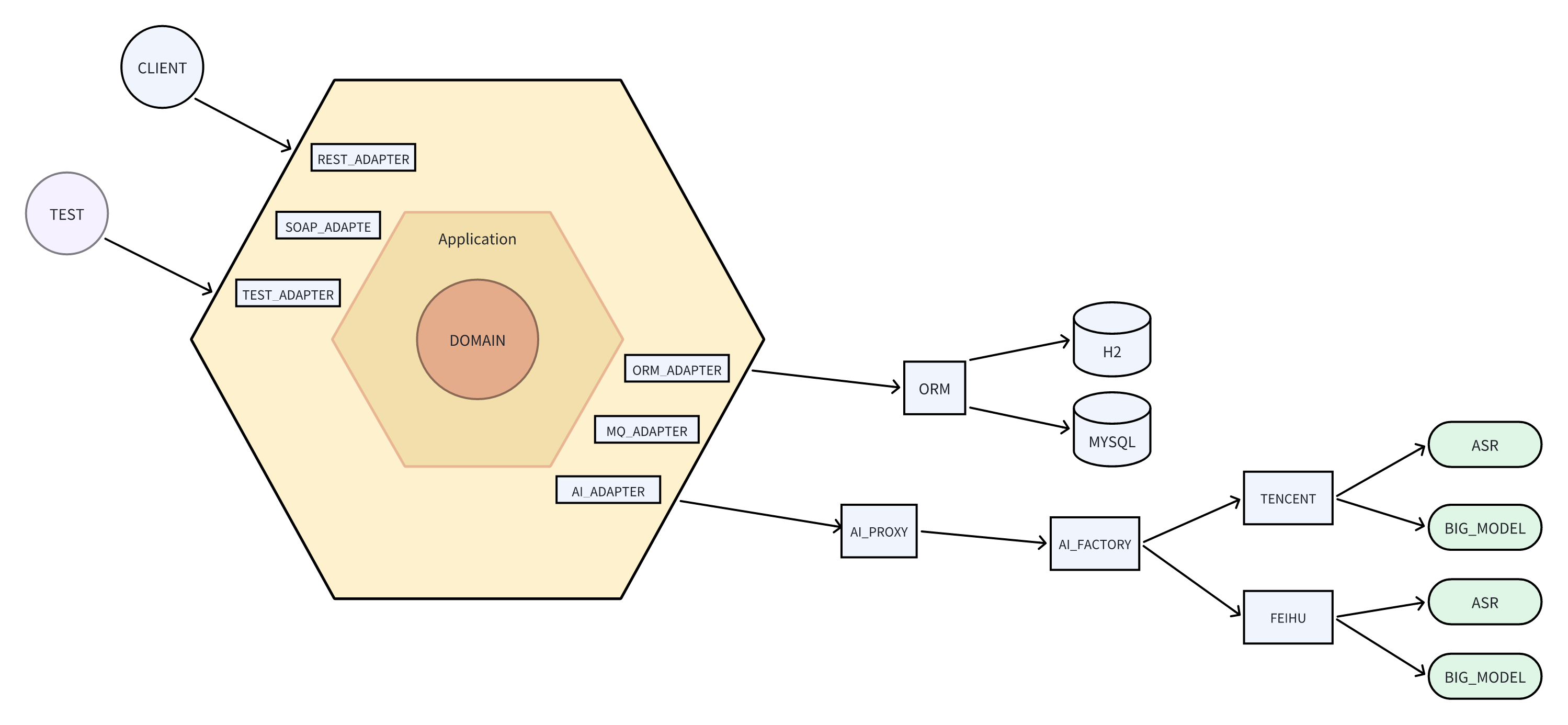
这里AI能力属于边界系统,边界系统的逻辑要和核心系统完全解耦,低耦合,不要把能力嵌入到核心业务代码中。不然后续改造肯定会影响到核心代码,这样后果一是改造困难工作量大,二是测试必须要大面积回归。
适配器也是天然的防腐层ACL(Anti-corruption layer),使得核心业务代码免受外部系统的侵害。
设计模式组合
综上所述,首先要用到接口适配器模式。为了实现多种需求,动态代理模式、工厂模式、策略模式和模板模式这四种主要的设计模式需要组合应用。
接口适配器:是核心思想,防腐且不干扰核心业务。
动态代理:可以在运行时动态修改接口参数,这样配置文件的信息可以动态的插入到实际的请求中,实现拦截请求更改方法参数的能力,这里使用的是cglib使用ASM字节码增强实现动态代理。
工厂+策略+模板:是经典的组合设计模式,可以横向扩展多种ai能力,也能纵向支持多个厂商的能力,在《设计模式之禅》一书中,作者认为这才是个完美的设计模式,工厂隐藏了策略细节,调用者不用关心具体的策略类,通过枚举可以将策略实现统一映射也避免了工厂和门面类的过度膨胀,策略类可以配合工厂进行多维度扩展,灵活可维护。
UML类图如下:
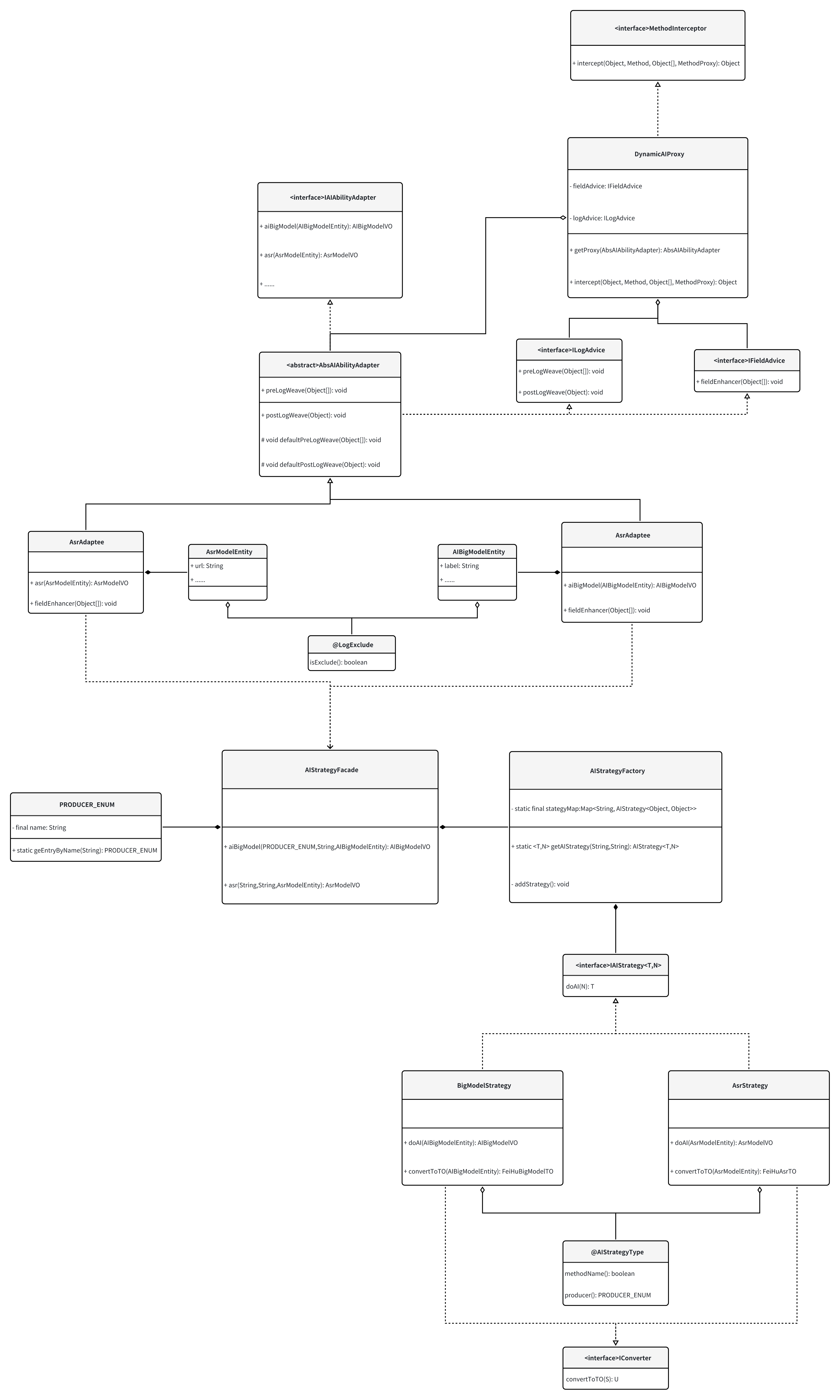
由图可以发现几个设计细节,动态代理织入了日志切面,日志切面会拦截请求前请求体和请求后返回值,这里对请求前参数拦截做了增强,可以选择日志打印imgBase64等信息也可以动态关闭打印无用字段信息,避免日志信息太多查找问题困难并且会导致日志文件过大的问题。此处也简化工厂和策略模式,策略根据自定义注解使用SPI机制直接加载到本地内存中,让工厂当成静态工具进行使用,策略也简化了调用流程。
可配置项分析
- 请求参数层面配置,用户请求参数可增强,可覆盖。
- ai接口置信度,可单独配置接口置信度。
- 接口层面,可配置访问频率限制,限流,接口日志打印,AI能力供应商。
- 服务层面,可配置AI服务负载策略。
- 外部系统,可配置客户端授权clientId,授权范围。
OAuth2.1 & OIDC1.0
简介
OAuth(Open Authorization)是一个关于授权(authorization)的开放网络标准,允许授权给第三方应用授权本服务资源权限,而且并不需要将用户密码提供给第三方应用,当前的OAuth协议版本是2.0。
OIDC (OpenID Connect) 是建立在OAuth2.0之上的身份层,在OAuth2.0授权的基础上添加了认证。OAuth2.0设计之初是为了API安全问题,就是接口的访问权限怎么能在不给账号密码的情况下进行安全控制,而OIDC在此基础上提供了获取用户信息,用户认证等标准。用户信息的获取也是调用API。可以认为OAuth2.0是父类,OIDC是子类,OIDC兼容OAuth2.0。
目前关于二者的定义,有以下主要名词术语需要理解:
| OAuth2.1 | OIDC | 含义 |
|---|---|---|
| EU End User | RS Resource Owner | 资源拥有者即用户 |
| RP Relying Party | Client Third-party application | 客户端 |
| RP Relying Party | Client Third-party application | 客户端 |
| OP OpenID Provider | AS Authorization Server | 认证服务 |
| Resource Server | RS Resource Server | 资源服务器 |
| Endpoint | Endpoint | 端点API |
| 无 | ID Token | 身份令牌(JWT)标识用户身份信息 |
| Access Token | Access Token | 访问令牌(JWT)适用于API访问鉴权 |
| User Agent | User Agent | 用户访问端 |
客户端分类
客户端分为两类
- Confidential Clients 机密型应用,能够安全存储凭证(client_secret),一般前后的分离项目或者后端集成前端的业务都是可以做到将密钥安全的保存到后端,并且不会暴露给用户。这样的系统推荐使用授权码模式。
- Public Clients 公共型应用,无法安全存储凭证(client_secret),比如SPA,移动端,数据存储在手机上,应当使用授权码+PKCE模式。
授权模式
目前有六种授权模式,java端spring-security-oauth2-authorization-server为我们提供了五种授权模式支持,抛开PKCE模式。
| 授权模式 | 说明 |
|---|---|
| 授权码模式 | |
| (Authorization Code) | 该模式要求必须有后端,可以安全存储client_secret。常见的微信,QQ扫码登陆就是用的此模式。 |
| 密码模式 | |
| (Password) | 服务内部使用,此模式代表了模块之间高度互信。 |
| 客户端凭证模式 | |
| (Client Credentials) | 服务间使用,M2M,微服务之间适合使用此模式。 |
| 隐式授权 | |
| (Implicit) | 不能安全存储client_secret情况下,可使用此模式,此模式没有Refresh Token。 |
| 设备代码模式 | |
| (Device Code) | 适用于受限设备。 |
| 授权码+PKCE模式 | |
| (Client Credentials) | 适用于SPA,桌面,移动端。 |
我们此次使用前两种授权模式,其中授权码模式提供给第三方应用授权使用,密码模式用于管理后台登录使用,项目目前是单体应用,暂时不扩展为微服务,所以暂时用不到客户端凭证模式。
授权码授权流程如下:
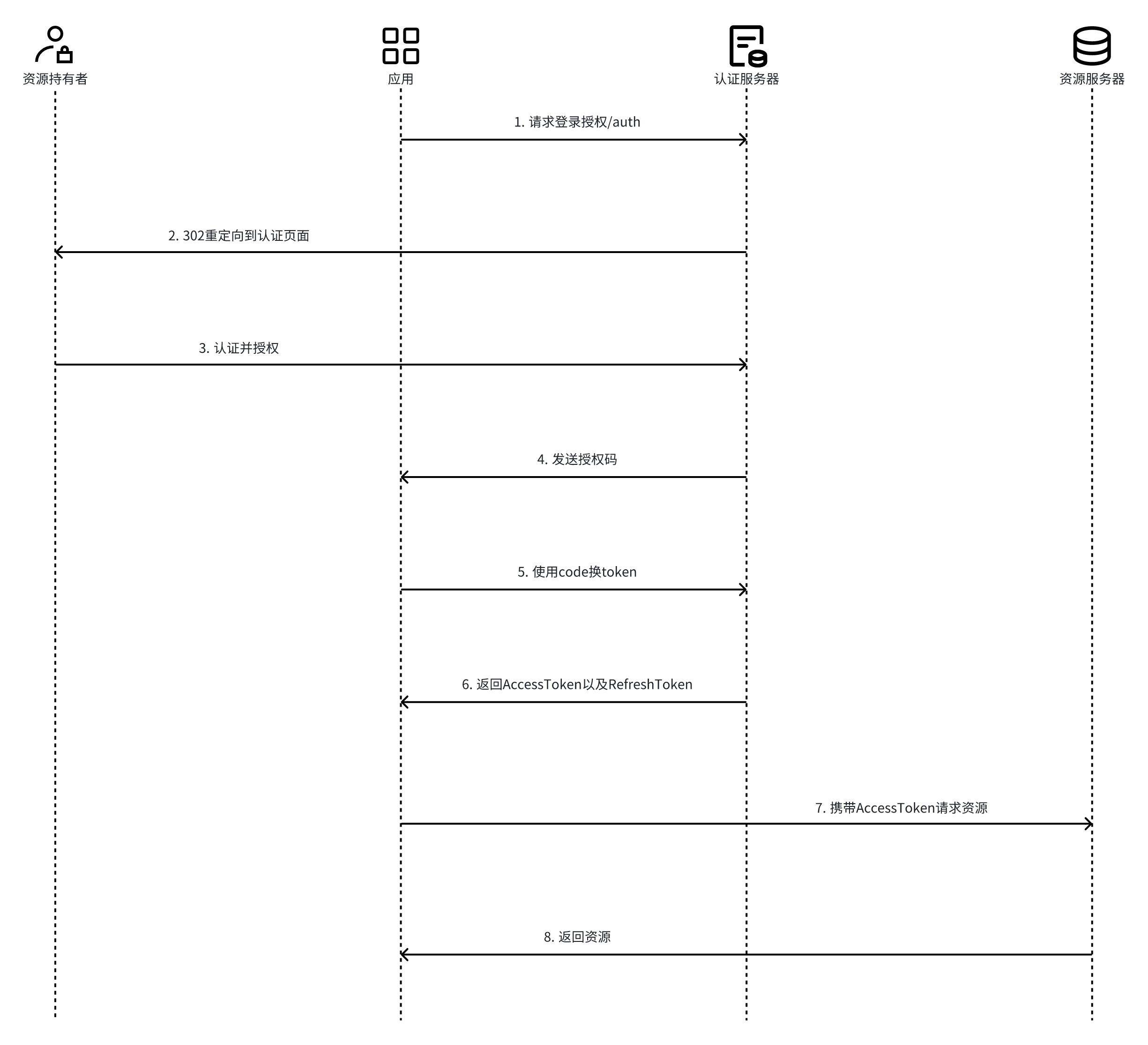
授权码模式,第三方系统需要先注册clientId到本管理后台,这是通用做法,可参考任一个开源项目做法:
密码授权模式流程如下:
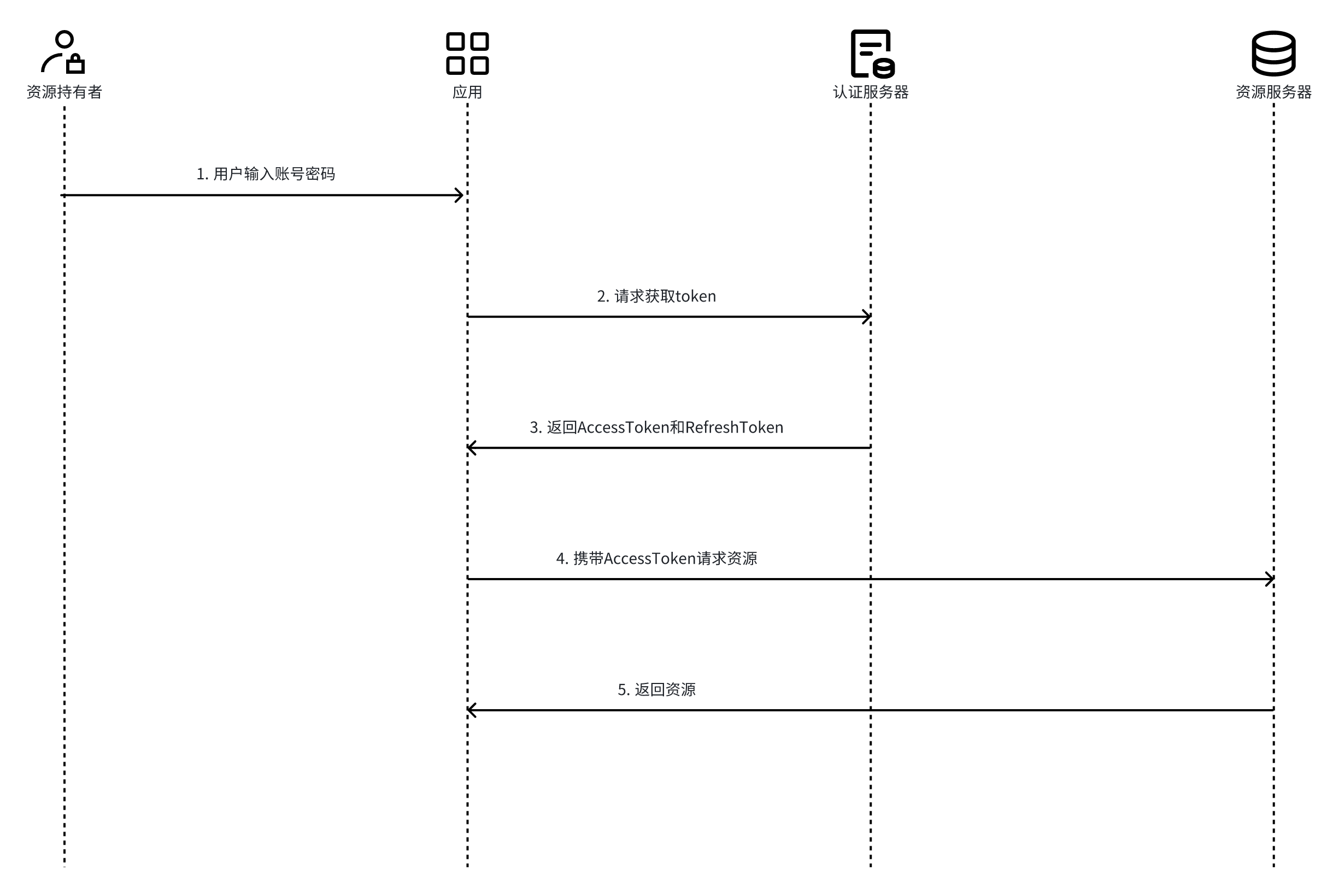
密码授权模式仅供自有后管系统登录使用。
负载均衡器
参照Ribbon负载均衡器,参考一致性hash。
多数据源
多数据源适配,抽离ORM。
限流熔断
Redis+Guava 是常用方案。
Raft协议
AI服务需要支持集群,如果是集群部署,多个Server需要对外提供统一服务,这就需要考虑分布式一致性问题。
选用Raft协议来解决分布式一致性问题,Raft协议由拜占庭问题引出,而拜占庭问题的探讨和研究离不开FLP定理和CAP定理。下面会简单梳理定理内容并引出Raft协议。
FLP 定理 & CAP 定理
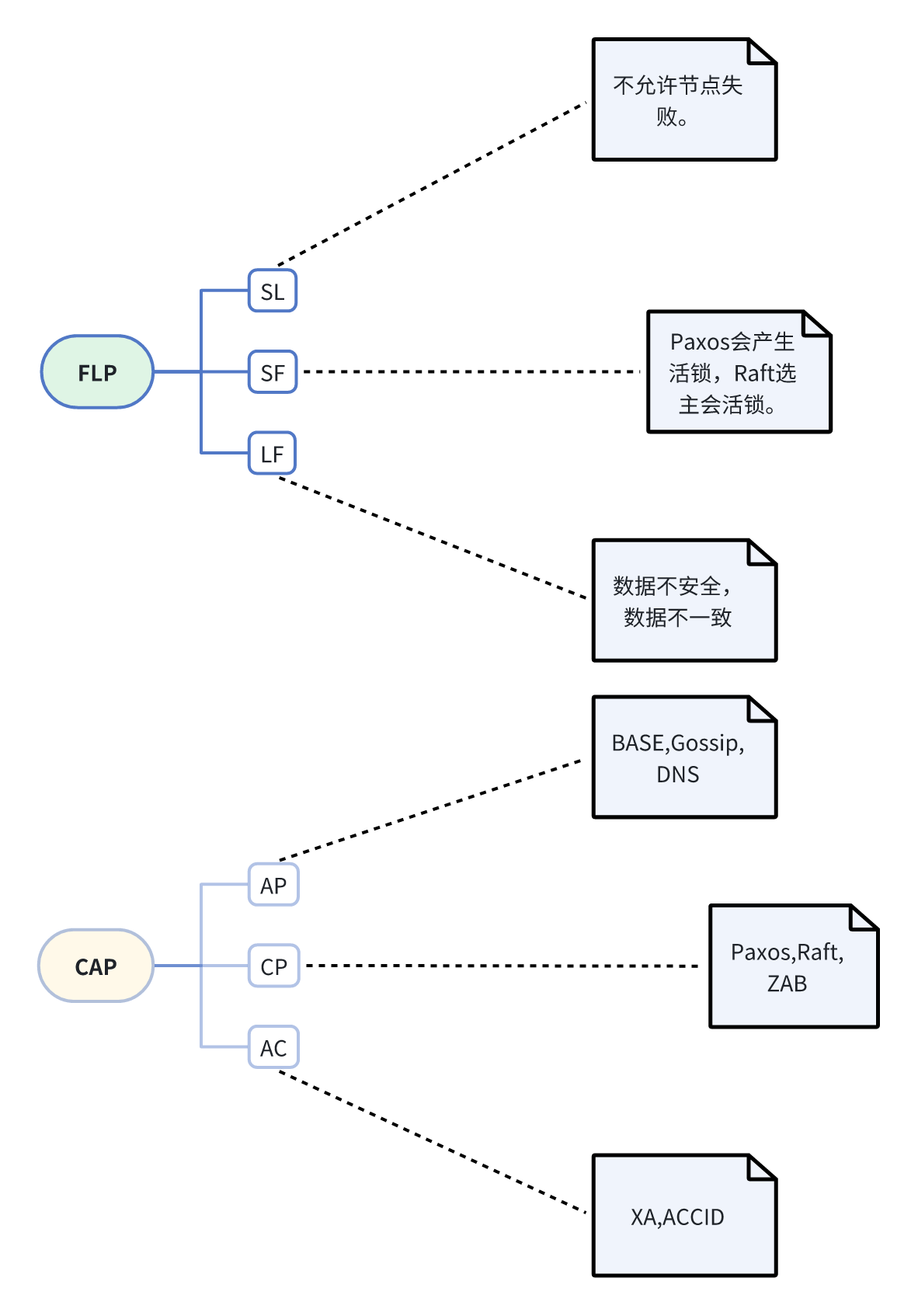
FLP
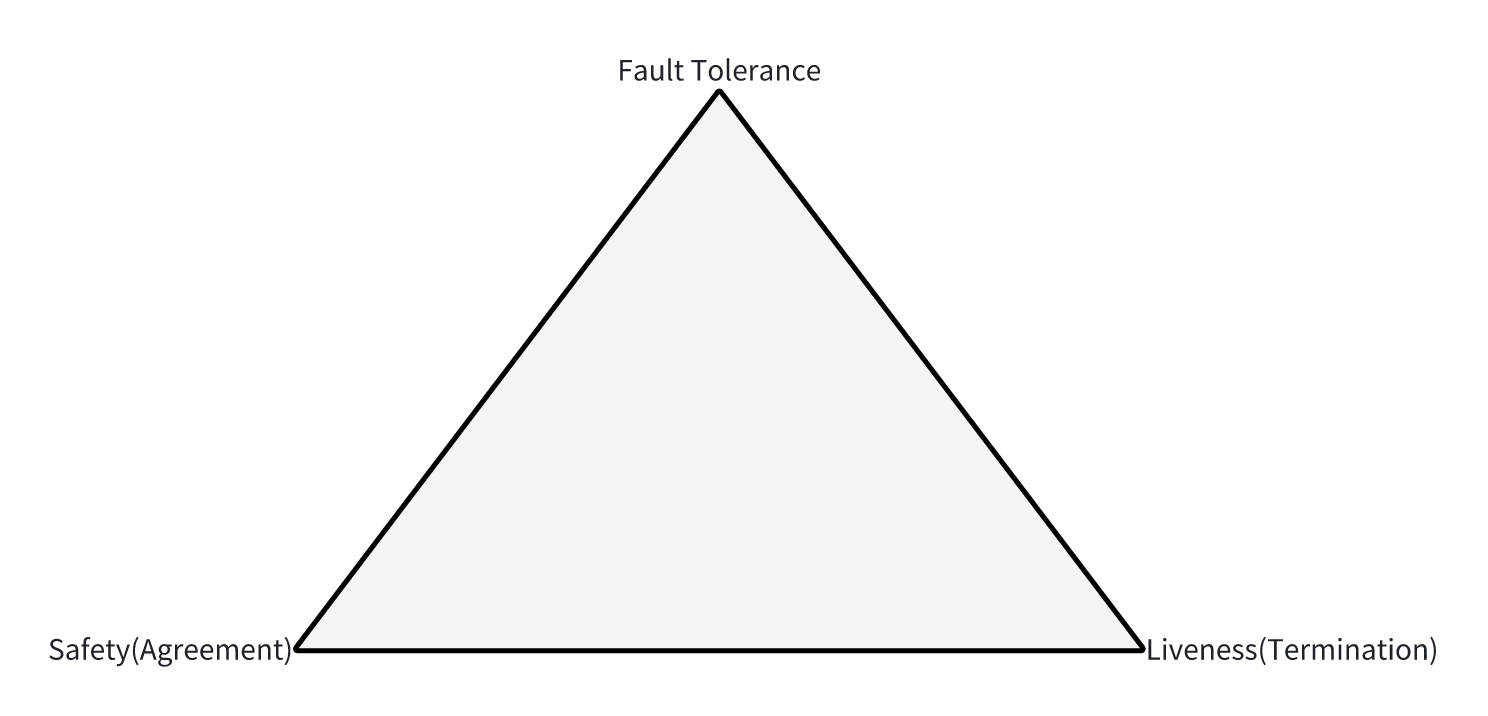
FLP Impossibility定理,该论文为《Impossibility of Distributed Consensus with One Faulty Process》1985年发表(It is impossible to have a deterministic protocol that solves consensus in a message-passing asynchronous system in which at most one process may fail by crashing),在网络可靠但允许节点失效(即使只有一个)的最小化一步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。
Safety包含三方面含义:
- Agreement: 不同节点最终完成决策的结果是相同的
- Validity: 决策得到的结果必须是某个合法节点提出的提案
- Uniform integrity: 每个节点最多只能做一次决定
Liveness: 一致性的结果可以在有限时间内完成,也称为Terminability
Fault Tolerance: 在节点故障时系统同样有效
FLP从理论上证明了在允许节点失效的情况下,异步系统中的liveness和safety是无法同时保障的,这给后续的理论研究和工程实现都划出了理论界限。比如: - 保障safety的场景:Paxos算法中没有解决活锁问题,即两个proposer交替的提出提案,但每个提案都没有得到批准的情况; 2PC(XA)在Coordinator或Participant出现节点故障时可能出现死锁,需要由Coordinator发起abort或者由Participant发起终止协议操作解决死锁问题。
- 保障liveness的场景:3PC保障了系统的liveness,但是在DoCommit阶段如果Coordinator和Participant出现网络超时,断连的Participant会继续进行事务的提交,如果此时正常工作的Participant已经执行了回滚操作,则系统出现数据不一致。
- 同时保障safety和liveness。raft、ZAB等协议是绕过了FLP的限制,在分布式共识过程中引入了同步或者半同步的故障检测器,识别出故障节点,确保正常节点达成共识。他们的理论基础来自Unreliable Failure Detector方法。
CAP
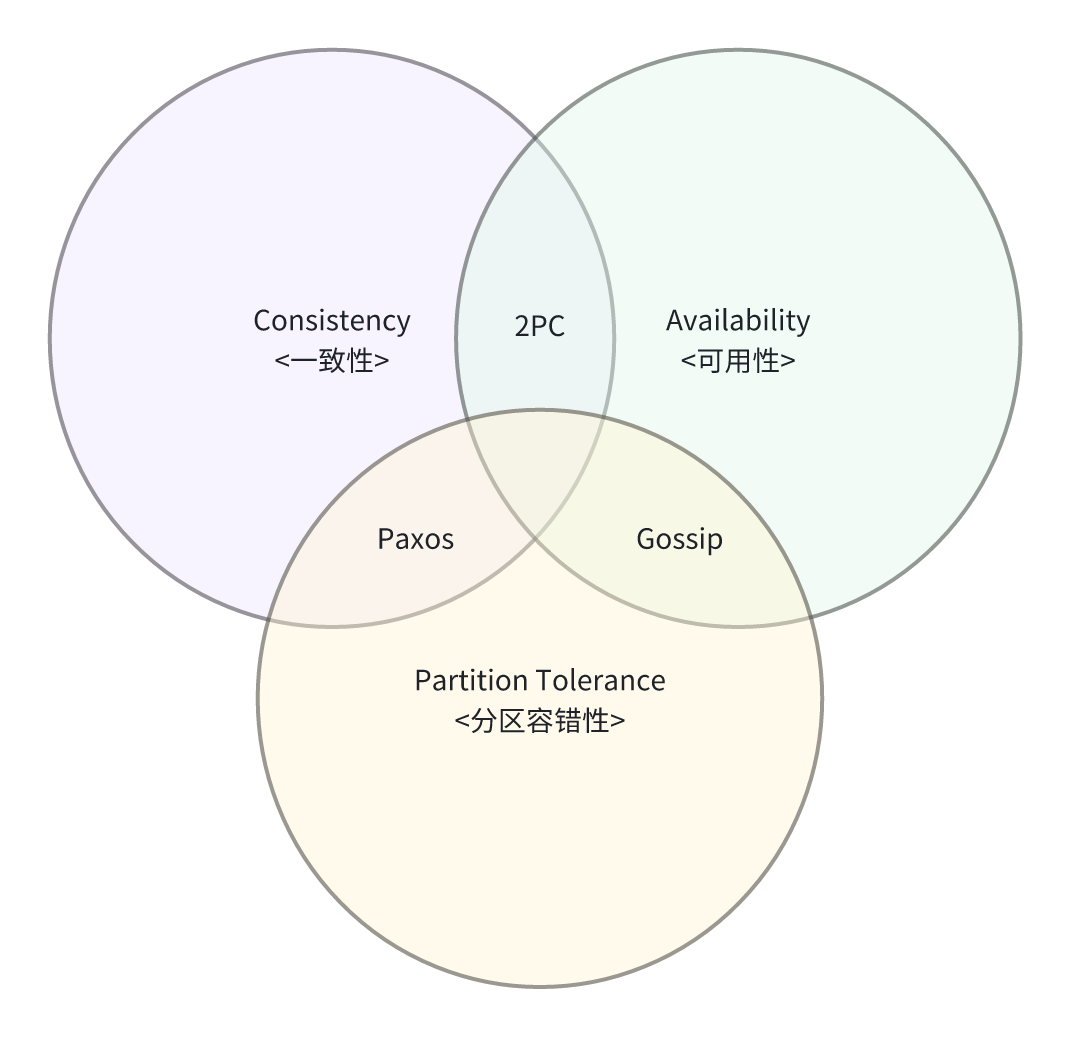
CAP猜想是在2000年,在2002年被证明,证明者之一Lynch也是FLP定理发表人之一,(It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: Consistency, Availability, Partition tolerance)分布式数据存储系统不可能同时满足一致性、可用性和分区容错性。
C: 所有分区数据同步最新后才对外提供服务,有任何分区数据不是最新,则不对外提供服务。
A: 每次请求都会得到响应,但不保证请求到的数据是最新的。
P: 分布式情况下能够提供服务。
CAP定理说明CAP不可兼得,需要根据需求有所取舍,比如弱化一致性(Gossip,BASE)或者弱化可用性(Paxos,Raft),或者弱化容错性(XA,ACID)。
举例,Zookeeper是CP,保证强一致性,返回一致性数据。Eureka是AP,弱一致性,允许部分节点数据不一致,返回的数据或许不是最新数据。Nacos兼容了CP和AP模式,CP保证配置文件强一致性,AP保证集群基本可用。
CAP不能兼顾,一般银行系统等P为必须,所以只能选择CP或AP,如果是CA就退化到单节点数据一致性,那么适用的就是ACID。
CAP是忽略网络延时的,对此PACELC理论做了补充,PAC就是CAP,E是else,L是Latency延时,C还是Consistency,当网络分区异常时,需要在A和C之间做权衡,当没有出现网络分区异常时,需要在L和C之间做权衡。
FLP和CAP描述的问题范围不同,FLP侧重分布式共识,Leader选举,CAP是数据复制,主从同步。FLP中故障类型是节点故障,CAP是分区故障。FLP可以通过引入同步或半同步的故障检测绕过FLP的约束,但是CAP是无解的。
BASE理论
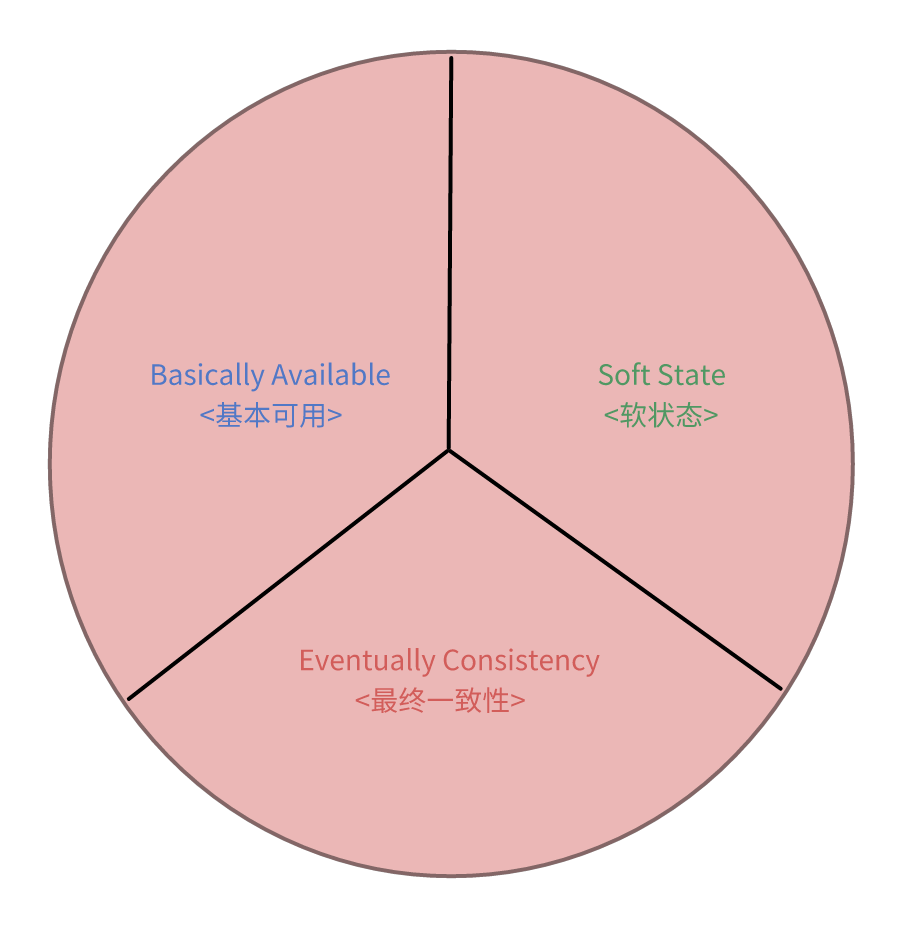
Basically Available: 是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用,支持分区失败。
Soft State: 没有一致性保证,允许系统存在中间状态,而中间状态不会影响系统整体可用性。
Eventually Consistency: 系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
BASE理论是CAP在AP方向上的延伸,考虑了网络延时和系统恢复后的状态:
- 使用柔性状态避免2PC。大事务切分小事务,分布式事务转化为本地事务。
- 保障最终一致性。为保证系统由柔性状态正确的切换到最终一致状态,需要考虑消息的幂等性、exactly once传递以及消息有序传递等。当MQ链路出现故障时,需要故障恢复机制。我们一般需要数据核对、异步事件恢复、数据补偿等发现和解决故障的技术方案,确保最终一致。
- 设计满足业务需求的"基本可用”系统。在服务层面,对服务模块分级。在极端情况下,利用熔断和降级机制确保核心业务链路稳定;在数据层面,遵循AKF立方体扩展规则。AKF-X轴扩展(多副本)可以使系统在出现分区时也能够保证一定的一致性(单调读一致性或者读写一致性等);AKF-Y轴扩展(按功能拆分)使我们可以单独为某一类数据进行性能优化和容量伸缩。
- 适当的使用缓存。对于较少改变、以读为主的数据可以使用缓存。总体来说,缓存就是要在存储约束、可用性需求、数据一致性等条件下最大化缓存的命中率,提升系统性能。这也是柔性状态和系统性能之间的权衡。
BASE的本质是在满足业务场景下,使用异步设计代替锁和同步等待,以“分布式事务”在可接受的时间内处于柔性状态的代价,换取系统的性能、可靠性和可扩展性,并确保柔性状态可以过渡到一致状态。
ACID
ACID是对数据库管理系统DBMS事务的约束,数据库的事务是指由一系列数据库操作组成的一个完整的逻辑过程,不可拆分。在共享数据场景下,一个事务对数据的修改,可能会影响到另外一个事务操作,就需要一些机制对其进行约束。
ACD最早是在1970年被Jim Gray提出,1983年Andreas Reuter和Theo Härder在此基础上增加了I,将首字母缩写ACID称为原子性,一致性,隔离性和持久性的简写。
ACID是数据库领域的重要原则,ACID不算是分布式领域的规则,ACID的C包含CAP里的C,ACID是CAP的AC侧。
拜占庭问题
由定理过来看具体的协议,但是协议之前还要清楚协议要解决的问题方向,一般来说从拜占庭问题开始。
拜占庭罗马帝国国土辽阔,每个军队都分隔很远,将军与将军之间只能靠信差传消息。战时,拜占庭军队内所有将军和副官必须达成一致的共识,决定是否有赢的机会才去攻打敌人的阵营。但是,在军队内有可能存有叛徒和敌军的间谍,左右将军们的决定又扰乱整体军队的秩序。在进行共识时,结果并不代表大多数人的意见。这时候,在已知有成员谋反的情况下,其余忠诚的将军在不受叛徒的影响下如何达成一致的协议,拜占庭问题就此形成。
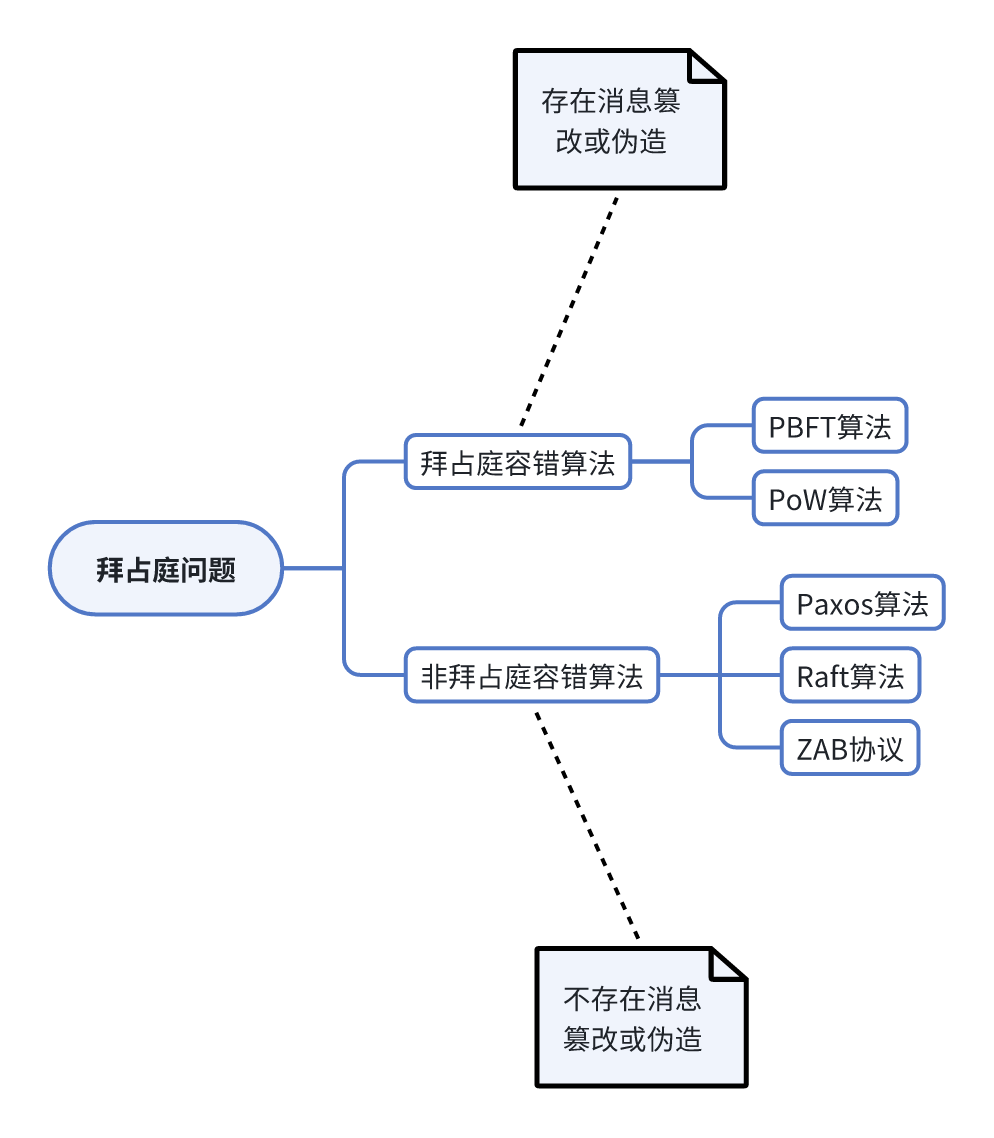
分布式一致性算法
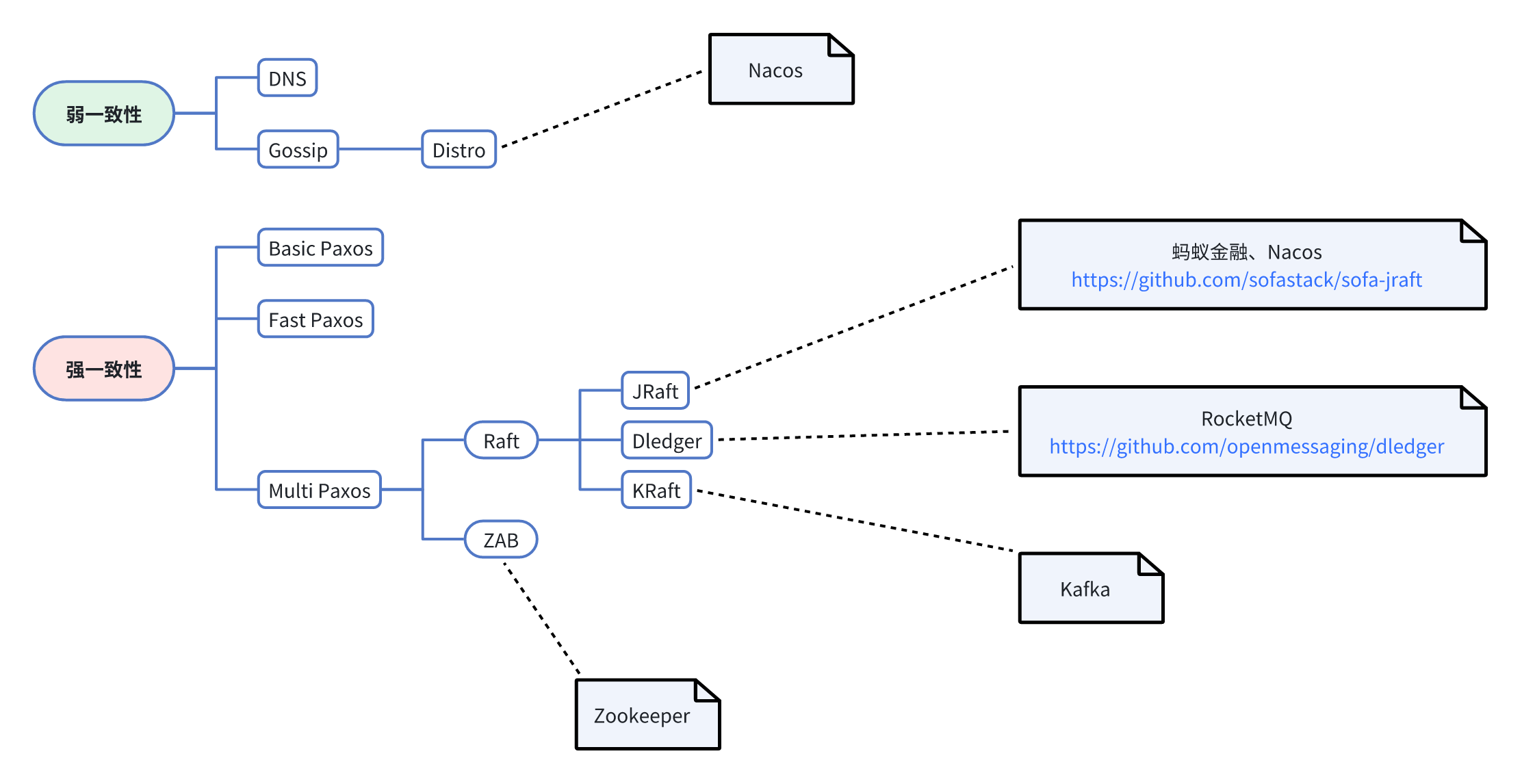
强一致性举例像Windows上的txt一样,一旦改动,所有打开此txt的页面都会改动,包括linux,同时编辑一个文件会做覆盖或退出等强异常提示。
弱一致性则不要求实时性,最终能保证一致即可,举例如Mysql的Binlog一样,会通过Relaylog逐步同步到从服务器,这就不要求实时性。
Raft协议介绍
Raft算法是由斯坦福大学的Diego Ongaro和John Ousterhout在2014年的《In search of an understandable consensus algorithm》论文中提出,是一种Multi-Paxos的重新简化设计和实现,设计目标有二: 易于理解、容易工程落地。
论文原文:
raft.github.io
动画演示:
Raft
Raft Consensus Algorithm
数据库设计
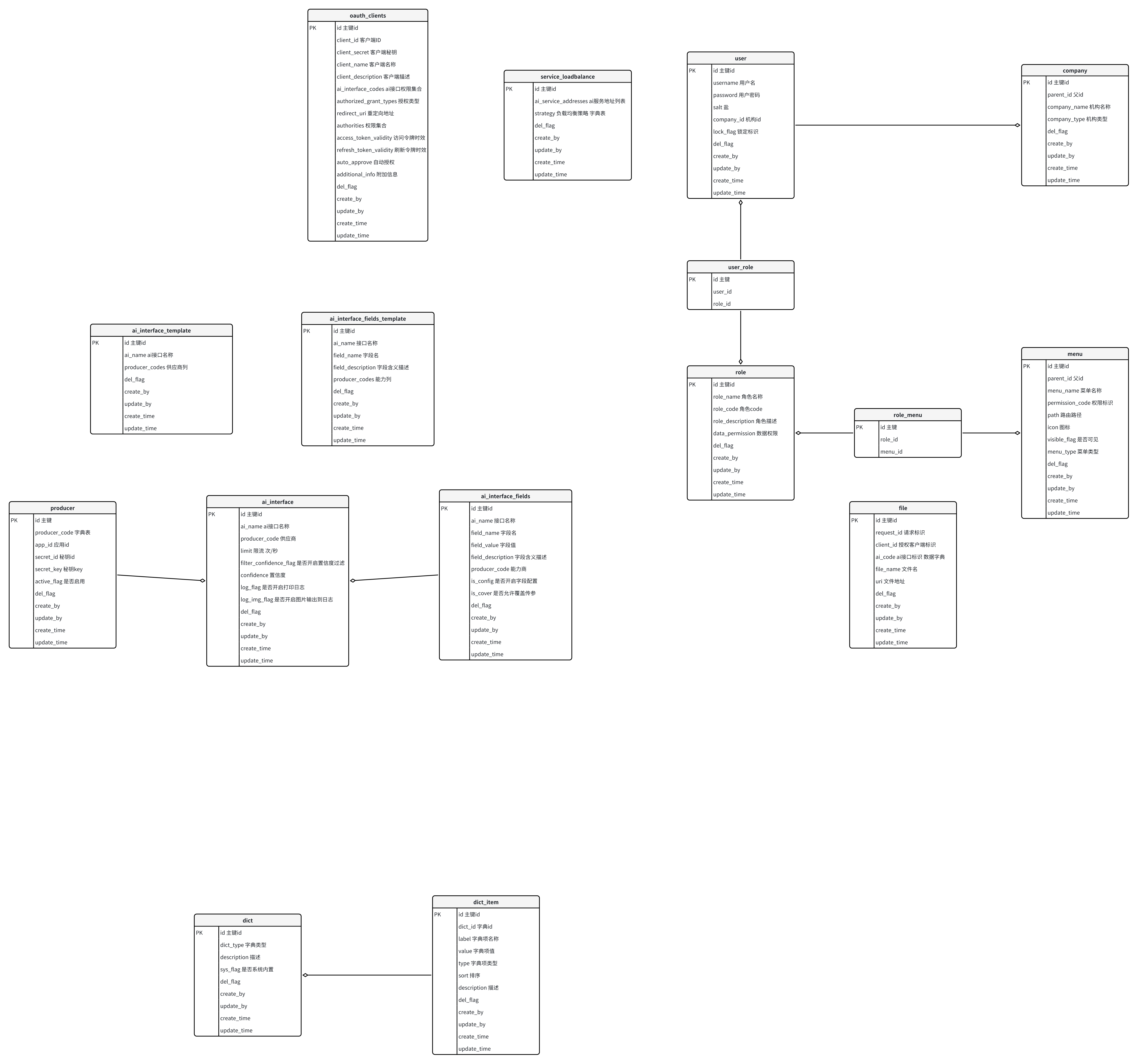
数据库需要用到的表大概如下:
第三方系统授权表:(主键ID,客户端标识,客户端秘钥,客户端名称,客户端描述,ai接口授权集合,授权类型,回调地址,权限集合,访问令牌时效,刷新令牌时效,自动授权,附加扩展信息)
AI接口配置表:(主键ID,ai能力标识,能力提供商标识,限流频次,是否开启日志打印,是否开启imgBase64打印,置信度过滤)
AI接口字段配置表:(主键ID,接口表主键ID,字段名,字段值,是否配置,是否允许覆盖传参)
供应商表:(主键ID,供应商标识,应用id,秘钥id,秘钥key,是否启用)
服务负载配置:(主键ID,AI服务地址列表,负载策略)
用户表:(用户ID,用户名,密码,盐值,机构id,是否锁定,是否删除)
用户角色表:(用户ID,角色ID)
角色菜单表:(角色ID,菜单ID)
角色表: (角色ID,角色名称,角色代码,角色描述,数据权限类型,数据权限范围)
菜单表:(菜单ID,菜单名称,权限标识,路由,父级菜单,菜单图标,是否可见,排序,菜单类型)
机构表:(机构ID,机构名称,父机构id,排序)
字典表:(主键ID,字典类型,描述,是否系统内置字段)
字典项表:(主键ID,字典ID,字典项名称,字典项值,字典项类型,排序,描述)
文件表:(主键ID,客户端标识,请求标识,ai接口标识,文件名,文件访问地址)
Q.E.D.


Comments | 0 条评论